Generative Hand-Object Prior
Method Overview
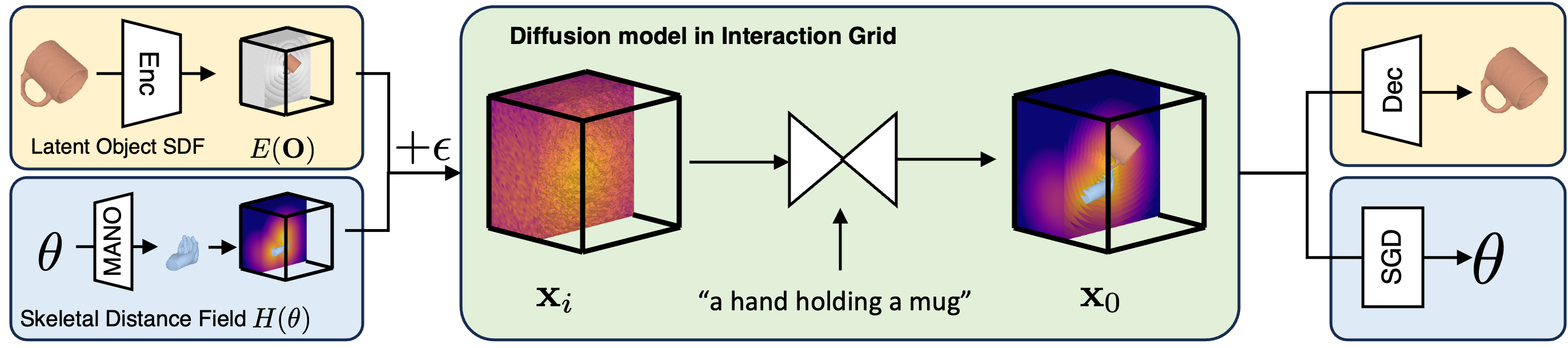
Hand-object interactions are represented as interaction grids within the diffusion model. This interaction grid concatenates the (latent) signed distance field for object and skeletal distance field for the hand. Given a noisy interaction grid and a text prompt, our diffusion model predicts a denoised grid. To extract 3D shape of HOI from the interaction grid, we use decoder to decode object latent code and run gradient descent on hand field to extract hand pose parameters.
HOI Generations
| Input | Output 0 | Output 1 | Output 2 | Output 3 | Output 4 |
|---|---|---|---|---|---|
| power drill | |||||
| spray | |||||
| plate | |||||
| wine glass |
Reconstructing Interaction Clips
Prior-Guided Reconstruction

We parameterize HOI scene as object implicit field, hand pose, and their relative transformation (left). The scene parameters are optimized with respect to the SDS loss on extracted interaction grid and reprojection loss (right).
Comparison with Baselines
 | |
Synthesizing Plausible Human Grasps
Prior-Guided Grasp Synthesis

We parameterize human grasps via hand articulation parameters and the relative hand-object transformation (left). These are optimized with respect to SDS loss by converting grasp (and known shape) to interaction grid (right).
Comparison with Baselines
We visualize the synthesized grasps by each methods.
| Input Object | GT | GraspTTA | G-HOP |
|---|---|---|---|