Shelf-Supervised Mesh Prediction in the Wild
in CVPR 2021

We aim to infer 3D shape and pose from a single image and propose a learning-based approach that can train from unstructured image collections, using only segmentation outputs from off-the-shelf recognition systems as supervisory signal (i.e. 'shelf-supervised').
We first infer a volumetric representation in a canonical frame, along with the camera pose for the input image. We enforce the representation geometrically consistent with both appearance and silhouette, and also that the synthesized novel views are indistinguishable from image collections. Then the coarse volumetric prediction is converted to a mesh-based representation, which is further refined in the predicted camera frame given the input image. These two steps allow both shape-pose factorization from unannotated images and reconstructing per-instance shape in finer details. We report performance on both synthetic and real world datasets. Experiments show that our approach captures category-level 3D shape from image collections more accurately than alternatives, and that this can be further refined by our instance-level specialization.
|
|
|
5min Narrated Video
Method Overview
 |
|
we first predict a canonical-frame volumetric representation and a camera pose to capture the coarse category-level 3D structure.
We then convert this coarse volume to a memory efficient mesh representation which is specialized according to instance-level details.
|

Paper
arxiv, 2021.
Citation
Yufei Ye, Shubham Tulsiani, and Abhinav Gupta.
"Shelf-Supervised Mesh Prediction in the Wild", 2021.
[Bibtex]
Code
Pytorch re-implementation
Qualitative Results
(click images for full resolution)
OpenImages 50 Categories
First, here is how we get the training set for one category (roughly)...
With the resulting image collections above, we just train a category-specific model and test!
| 0-Guitar |  | 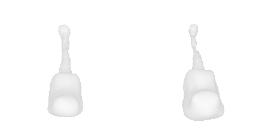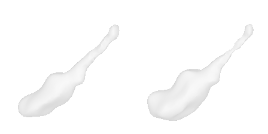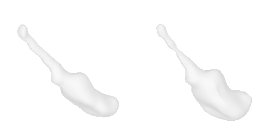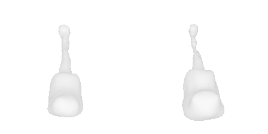 | 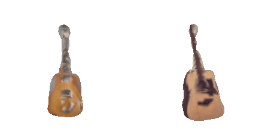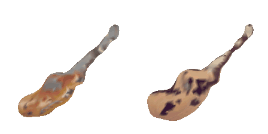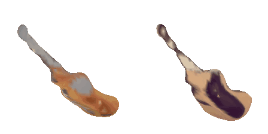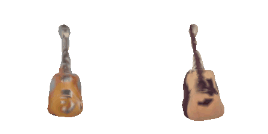 | 1-Rose |  | 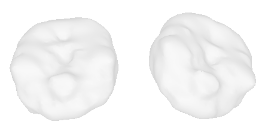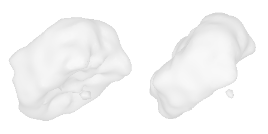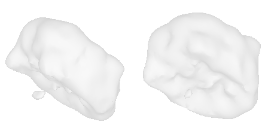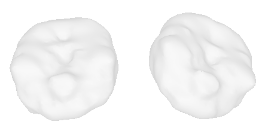 |  |
| 2-High-heels |  | 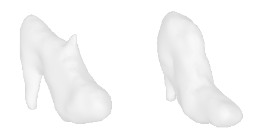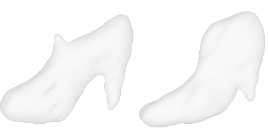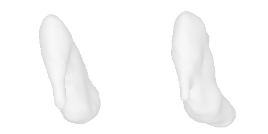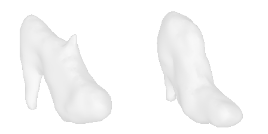 |  | 3-Flower |  | 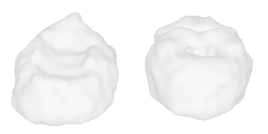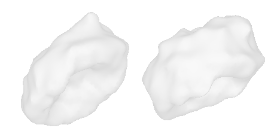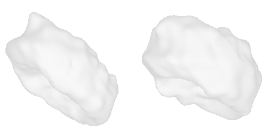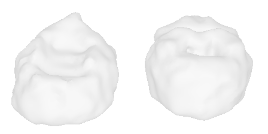 |  |
| 4-Handbag |  |  |  | 5-Goat |  | 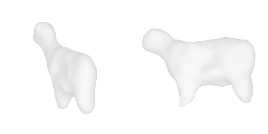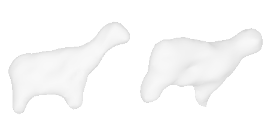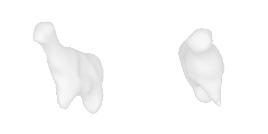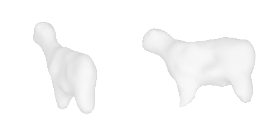 | 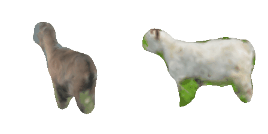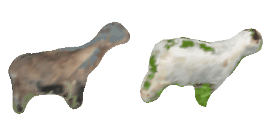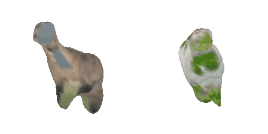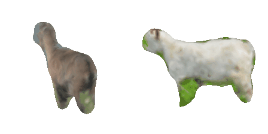 |
| 6-Coffee-cup |  |  |  | 7-Eagle |  |  |  |
| 8-Giraffe |  |  | 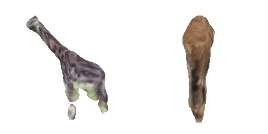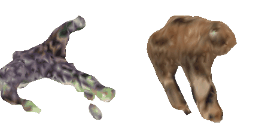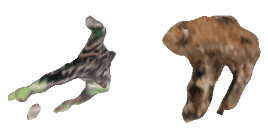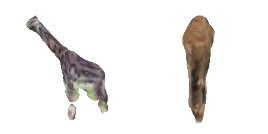 | 9-Sun-hat |  |  |  |
| 10-Starfish |  |  |  | 11-Cocktail |  |  |  |
| 12-Fedora |  |  |  | 13-Motorcycle |  |  | 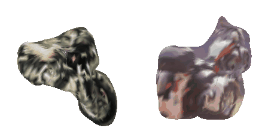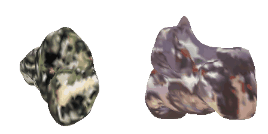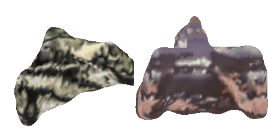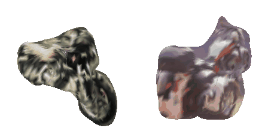 |
| 14-Strawberry |  | 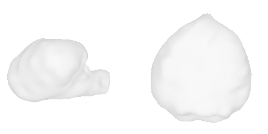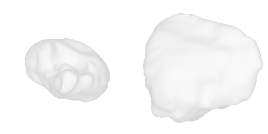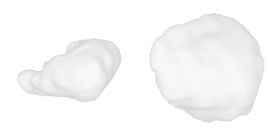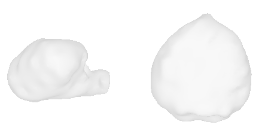 |  | 15-Christmas-tree |  |  |  |
| 16-Hat |  | 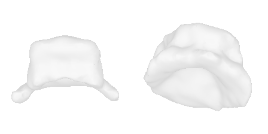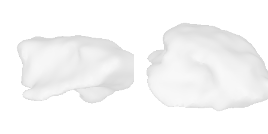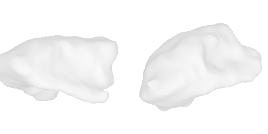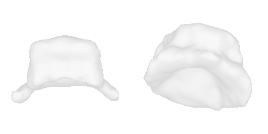 |  | 17-Laptop |  |  |  |
| 18-Cattle |  | 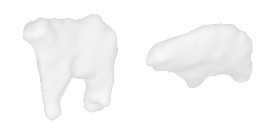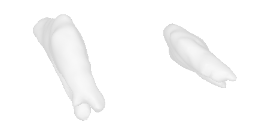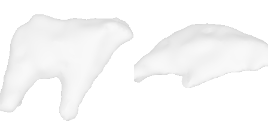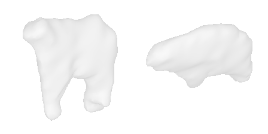 | 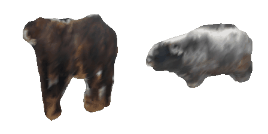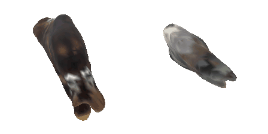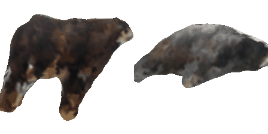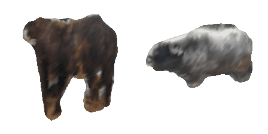 | 19-Orange |  |  |  |
| 20-Swan |  |  |  | 21-Candle |  |  |  |
| 22-Roller-skates |  | 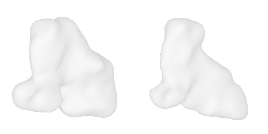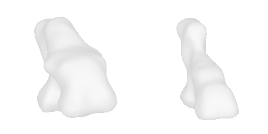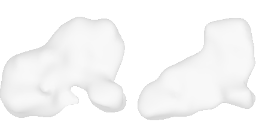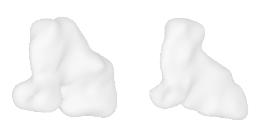 |  | 23-Skateboard |  |  |  |
| 24-Boot |  |  |  | 25-Mushroom |  |  | 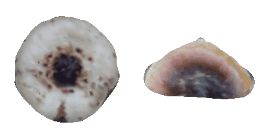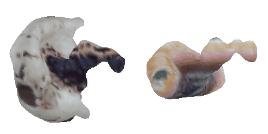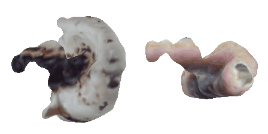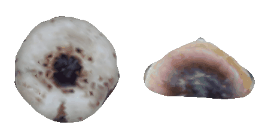 |
| 26-Cowboy-hat |  |  |  | 27-Chicken |  | 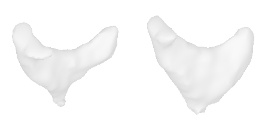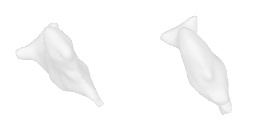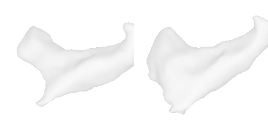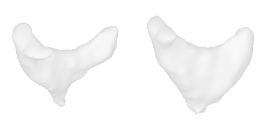 |  |
| 28-Mug |  | 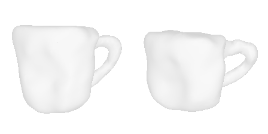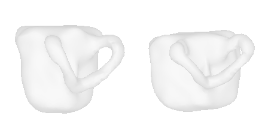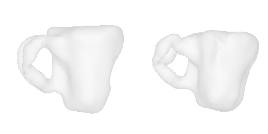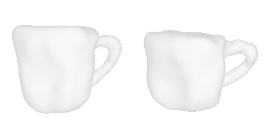 |  | 29-Surfboard |  |  |  |
| 30-Waste-container |  | 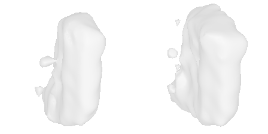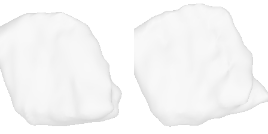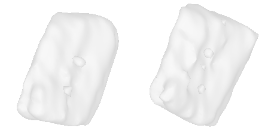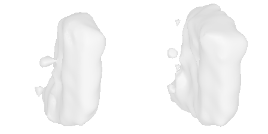 |  | 31-Sofa-bed |  |  |  |
| 32-Goldfish |  |  |  | 33-Saxophone |  |  |  |
| 34-Canoe |  |  |  | 35-Bagel |  | 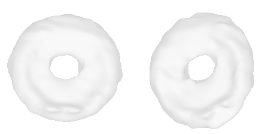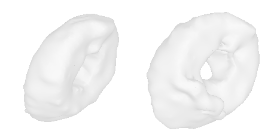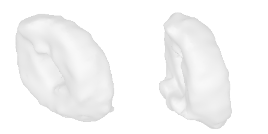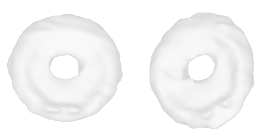 | 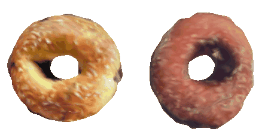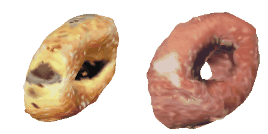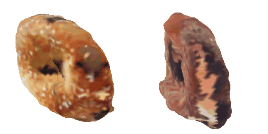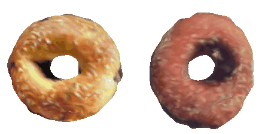 |
| 36-Horse |  |  |  | 37-Skyscraper |  |  |  |
| 38-Bicycle-wheel |  | 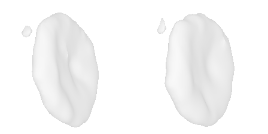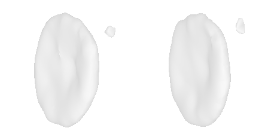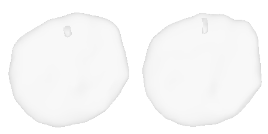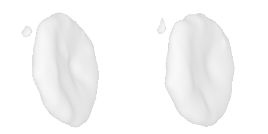 |  | 39-Airplane |  |  |  |
| 40-Vase |  |  | 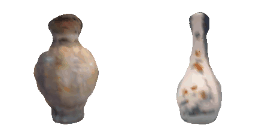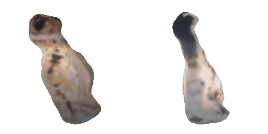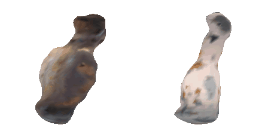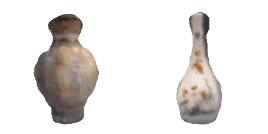 | 41-Tap |  | 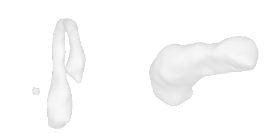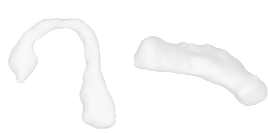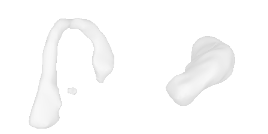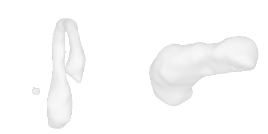 |  |
| 42-Owl |  |  |  | 43-Microwave-oven |  |  |  |
| 44-Pig |  | 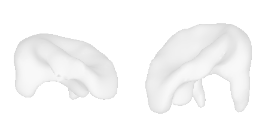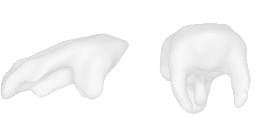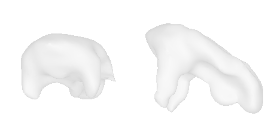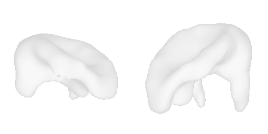 |  | 45-Pillow |  |  |  |
| 46-Backpack |  |  |  | 47-Toilet |  |  |  |
| 48-Balloon |  |  |  | 49-Flowerpot |  | 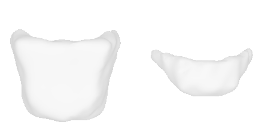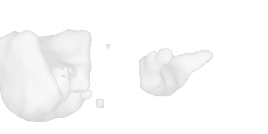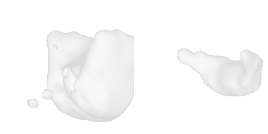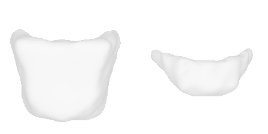 |  |
| 50-Truck |  |  |  | 51-Teddy-bear |  |  |  |
| 52-Beer |  |  | 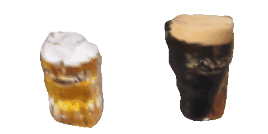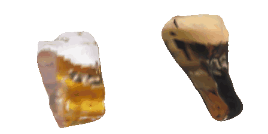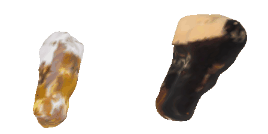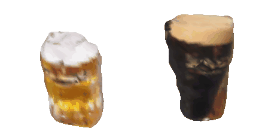 | 53-Spoon |  |  |  |
| 54-Bird |  |  |  | | | | |
Further, the pretrained category-specific models can be integrated and directly applied on COCO!
See more results on curated (CUB, Quadrupeds, Chairs-in-the-wild) and synthetic (aeroplane, car, chairs) dataset.
Acknowledgements
The authors would like to thank Nilesh Kulkarni for providing segmentation masks of Quadrupeds. We would also like to thank Chen-Hsuan Lin, Chaoyang Wang, Nathaniel Chodosh and Jason Zhang for fruitful discussion and detailed feedback on manuscript. Carnegie Mellon Effort has been supported by DARPA MCS, DARPA SAIL-ON, ONR MURI and ONR YIP.
This webpage template was borrowed from some GAN folks.
|