Object-centric Forward Modeling for Model Predictive Control
Yufei Ye Dhiraj Gandhi Abhinav Gupta Shubham Tulsiani
Carnegie Mellon University Facebook AI Research
in CoRL 2019
Paper | Poster | Bibtex
|
|
Method Overview
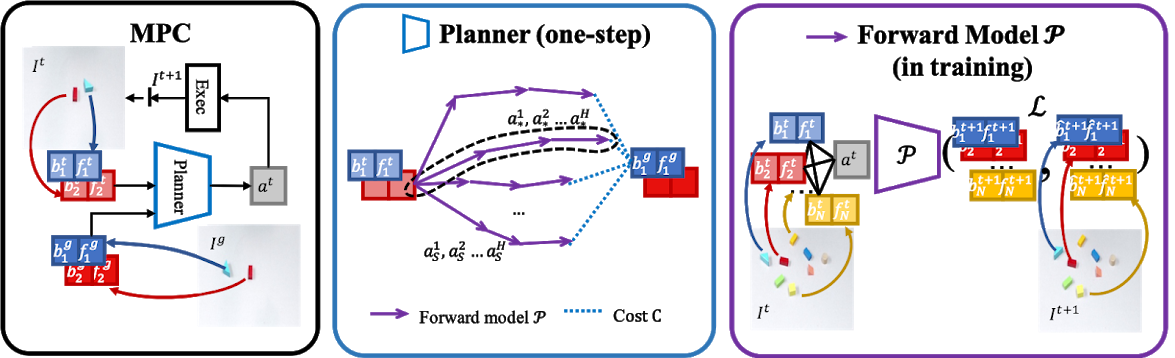 |
| Left: We demonstrate MPC in testing time. Given a goal and initial configuration, the planner takes as input the object-centric representation (section 3.1) and outputs an action to execute. Then, a new observation is obtained to repeat the loop. Middle: Inside the planner, several action sequences are sampled and unrolled by the forward model (section 3.2). The best sequence with respect to the cost is selected, among which only the first action is executed (section 3.3). Right: The forward model P takes as input a representation of a scene with an action and predicts the next step. It is supervised by the ground-truth representation of the future. |

Paper
arxiv, 2019.
Citation
Yufei Ye, Dhiraj Gandhi, Abhinav Gupta, and Shubham Tulsiani.
"Object-centric Forward Modeling for Model Predictive Control", in CoRL, 2019.
Bibtex
Code & Data
code / Synthetic / Sawyer
BibtexTraining Set Snapshots
Predictors are only trained with one-step
 |
 |
 |
 |
 |
 |
 |
 |
Qualitative Results in Simulation
Red: initial configuration; Blue: goal configuration
(click to view full resolution)
 |
 |
 |
 |
 |
 |
Qualitative Results on Sawyer
Pass around Objects |
 |
Flip Objects |
 |
Novel Objects |
 |
Ablation Study
Without Interaction Network (No-IN)
 |
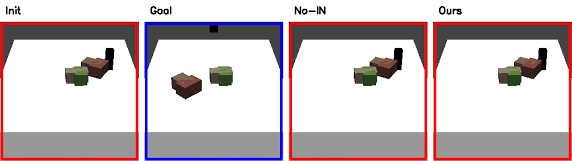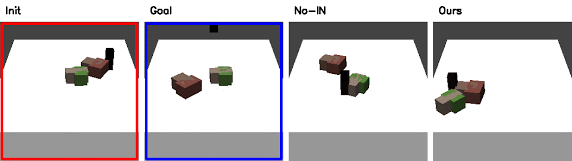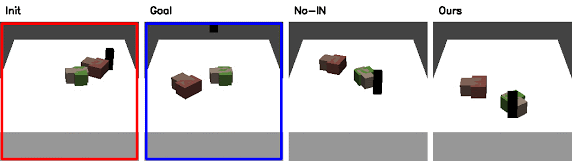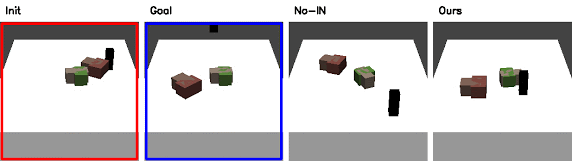 |
Prediction
Unroll t=0 for T times with ground truth action.
Note: Prediction t+1 should be more consistent with predicted current state (t+1) than ground truth, since prediction is not perfect at any time.
 |  |
 |  |
Visualizing Correction Model
Green: Ground Truth; Brown: Prediction; Red: Corrected Prediction
 |
 |
 |
 |
Failure cases
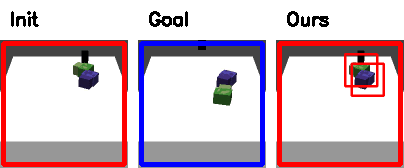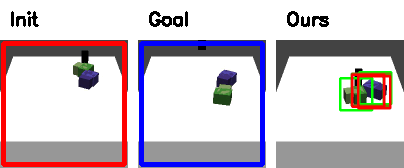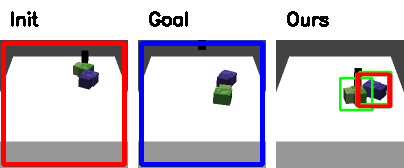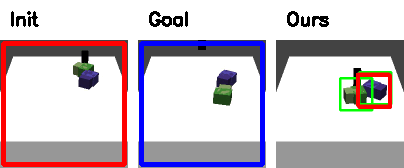 |
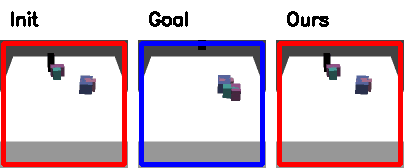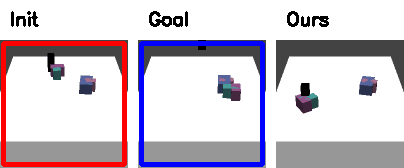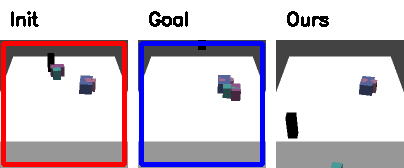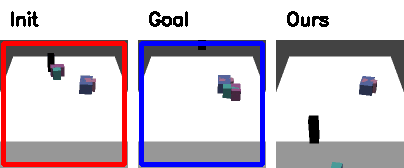 |
| Track the wrong object. | Push off the table |
Acknowledgements |
