Compositional Video Prediction
Yufei Ye Maneesh Singh Abhinav Gupta* Shubham Tulsiani*
Carnegie Mellon University Facebook AI Research Verisk Analytics
in ICCV 2019
Paper | Code | Poster | Bibtex
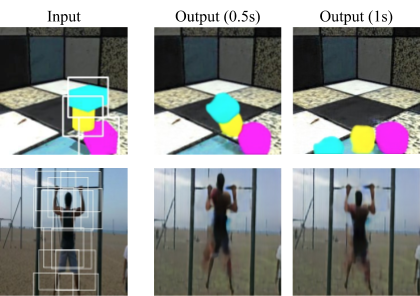 |
|
|
Method Overview
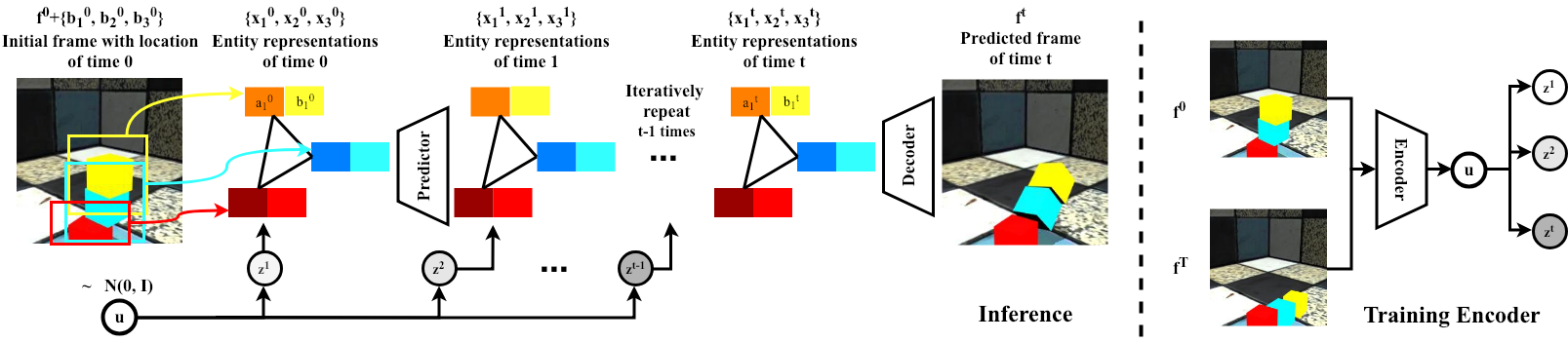 |
| Our model takes as input an image with known/detected location of entities. Each entity is represented as its location and an implicit feature. Given the current entity representations and a sampled latent variable, our prediction module predicts the representations at the next time step. Our learned decoder composes the predicted representations to an image representing the predicted future. During training, a latent encoder module is used to infer the distribution over the latent variables using the initial and final frames. |

Paper
arxiv, 2019.
Citation
Yufei Ye, Maneesh Singh, Abhinav Gupta, and Shubham Tulsiani.
"Compositional Video Prediction", in ICCV, 2019.
Bibtex
Code
ShapeStacks Results
Results by Entity Predictors
(Click to view full resolution)
 |
 |
 |
 |
Generalization to more blocks (train with 3 blocks)
(Click to view full resolution)
 |
 |
 |
 |
 |
 |
Visualization of five randomly sampled future predictions
(Click to view full resolution)
 |
 |
Penn Action Results
(Click to view full resolution)
 |
 |
 |
 |
 |
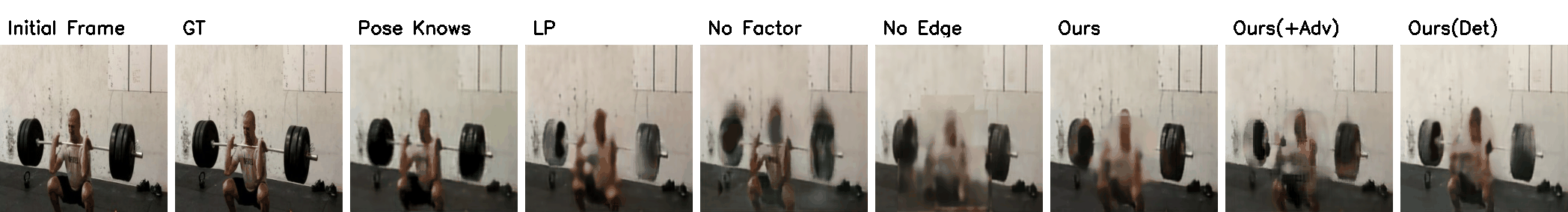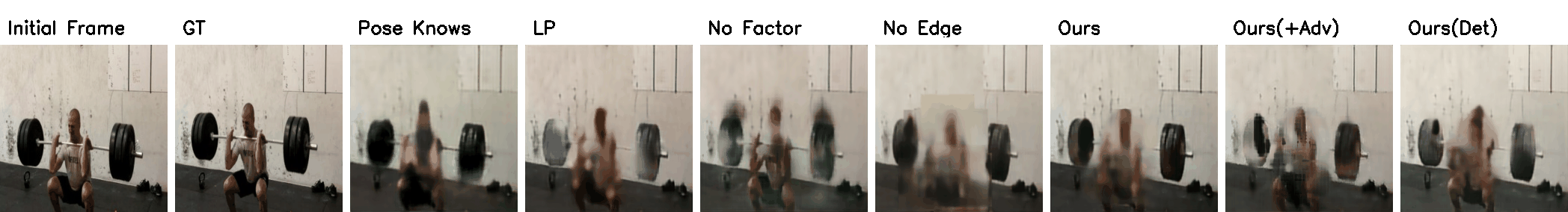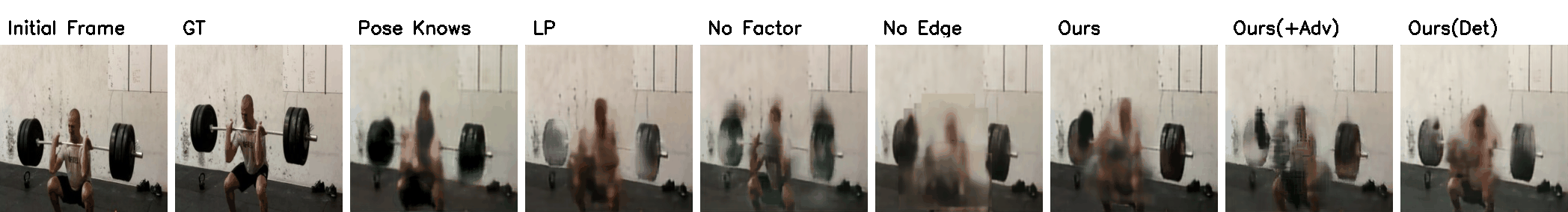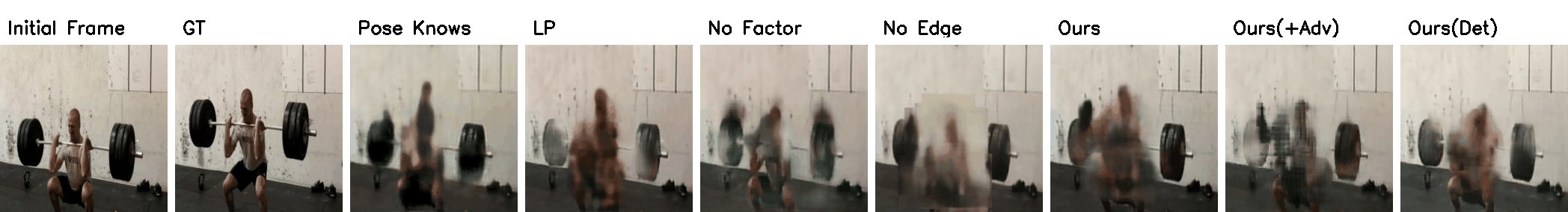 |
 |
 |
 |
Visualization of three randomly sampled future predictions
(Click to view full resolution)
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Acknowledgements |
